十四、文本指针
之前我们在研究《超时空要塞7》的文本编辑时(第五节),曾经强调过替换文本时,每一段话开头的位置一定不要改动。这里会涉及到文本指针的问题。
游戏中在运行到某个需要输出文本的地方时,会通过某种方式计算中一个地址,这个地址指向将要在这里输出的文本,我们把这个地址叫做文本指针。大部分游戏会把这些文本指针统一保存在游戏中的某一个地方,需要的时候把这个指针地址读出来,再按照这个地址去读文本。
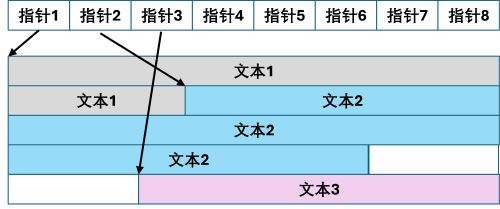
所以在不改变指针的情况下,每块文本的长度是固定的,我们在修改文本时,就必须保证新文本的字节数不能超过原来的文本。但对于稍微有点文字的游戏来说,用到的汉字基本都会超过256个,所以我们最后肯定得用双字节来编码一个汉字。虽然汉字的信息密度比日文要高,但要想用一半数量的汉字来翻译还是有难度的,因此我们必须要想办法扩展每一段文本的长度。
最简单的方法就是去修改指针,我们可以按照翻译好的文本去重新生成一套指针,这样就不受文本长度的限制,像之前翻译《钟为蛙鸣》时就这样做的。在《钟为蛙鸣》中,所有的文本都是连续的放在一起的,并且每段文本之间除了和对话框相关的控制符之外没有其他代码,改变指针地址不会对游戏有影响。翻译完成后,根据文本长度重新计算生成一下指针,就可以很方便的完成文本的导入工作。
但对于《圣剑传说》这样文本与文本之间还有大量代码的游戏则不太好办,我们暂时还不清楚这些代码和文本之间有没有什么关联,文本指针是否会指向这些代码。那我们就先来看看能不能把《圣剑传说》的文本指针找出来。
这里还是要用到BGB调试器的追踪功能,这次是要找什么时候从游戏的Rom中读出文本的地址。我们还是以第一句的文本来示范,文本的地址是D:46F1,我们在读取这句文本这里设置断点。
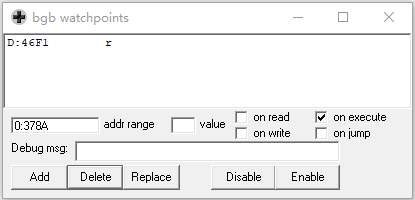
程序停在这里从D:46F1读出文本

此时,hl中地址是46F1,我们往回追踪,找这个46F1是从哪里来的。然后可以看到46F1是从D8B6,D8B7这里读出来的。
ld a,(D8B7)
表示把D8B7这个地址上的值写到a中
ld h,a
再把a的值写到h
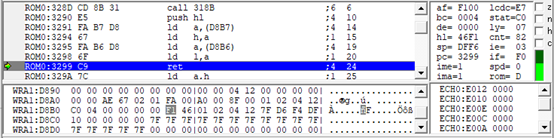
但D开头的地址是WRAM,这里的地址是通过读写或计算保存在这里的,并不是我们想要的游戏Rom中的地址,要继续往回追踪。接下来我们就看什么时候往D8B6写F1,往D8B7写46。修改追踪点如下
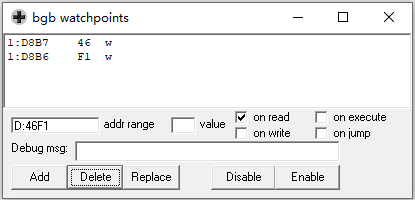
我们看到,当游戏进入第一个场景时,就会向D8B7写46,同时向D8B6写D9
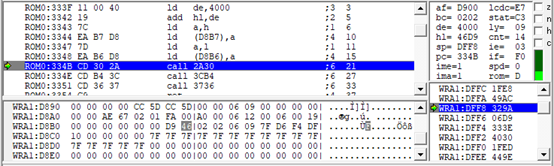
而且之后会不断向D8B7写入46,这太影响我们追踪了,我们就只追踪D8B6的变化。在这里,程序把当前hl的地址46F1保存到D8B6,D8B7。
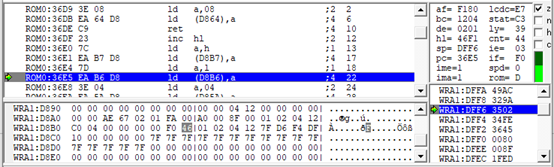
而这个46F1是通过0:36DF的程序
inc hl
得到的,这一句的意思是把hl对应的地址增加1,之前hl是46F0,接下来我们就要追踪46F0是怎么来的。这个过程会比较繁琐,也是我们运气比较差,选到一个包含很多控制符的文本。最终我们来到刚进入游戏时把46D9写到D8B6,D8B7这里。继续追踪,这里hl中是06D9,
ld de,4000
给de赋值4000
add hl,de
把de与hl相加,相加后的地址写到hl

所以接下来看06D9是怎么来的。终于在这里我们看到是从D:402E,402F这里读出的06D9,然后06D9在加上4000得到这一部分文本(包含控制符)的地址4609。
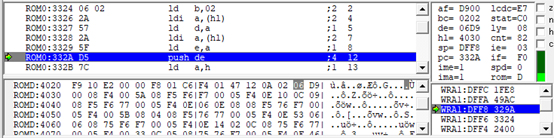
因此,06D9就是第一段文本的指针。但是观察前后的代码,其它的代码并不像是文本的地址。如果以第二段文本去查找指针的话,会发现它对应的指针在很远的地方,完全看不出有什么规律。
所以对于《圣剑传说》这个游戏来说,不能通过简单的修改指针来扩充文本的字符数,需要想其它的办法。我们得考虑一个替代的方案,总的思路还是让文本读写的程序在读到这里时跳到新的文本地址去读写文本,从而绕开文本长度的限制。类似这个游戏里20-3F的这些短语的效果,之所以能实现读一个字节输出一长串文本,就是因为当程序读到这些短语时,会跳到Bank 0中那些短语那里去读取文本并输出。
虽然最终的汉化没有用上文本的指针,但在其他很多游戏的汉化中还是会用到这种方法,所以这里花了比较多的篇幅介绍了大致的过程。这种追踪的方法在查找文本、字库,修改程序等很多地方都会用到,并且可以让我们熟悉游戏中的程序,以及Z80汇编程序中的各种命令,为后面修改程序做好准备。