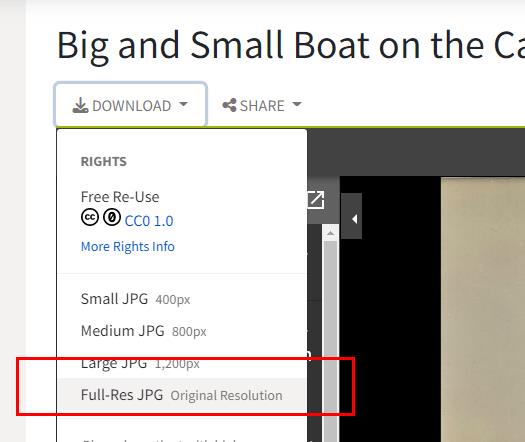
https://repository.duke.edu/dc/gamble?f%5Bseries_ssim%5D%5B%5D=Sojourn%2C+1908%3A+China
手动一个一个下载太慢了
wenbin5243 看看图片命名有没有规律,有就用迅雷批量下来,没有就找个爬虫脚本改一改
vDtv3vNZoE5d
vDtv3vNZoE5d 让Gemini写了个爬虫,试了下可以下载,用图片描述来命名下载的图片。将下面的代码保存到 download.py命令行中输入 Python3 download.py  ...
vDtv3vNZoE5d 能用,安装好Python3和依赖库,在CMD里输命令运行。或者你直接在书格网搜,我看了一些图片才想起来以前在书格网下载过PDF版,那里的也是从这个网站里下载整合的。
Downie能用么?别花钱!
https://bbs.oldmantvg.net/thread-54642.htm
vDtv3vNZoE5d 不用,网址和下载规则已经写在代码里了,直接运行就能下载。
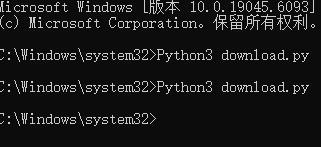
好像没有运行
哈哈,没动静肯定是哪一步我没做好
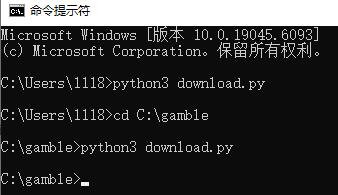
vDtv3vNZoE5d 输入python3看一下,可能是安装时没勾选添加环境变量