darksidedxp
也刚接触这方面,问一个a卡要比n卡差很多吗?比如弄块rx7700 xt能和n卡啥级别的显卡相比?
darksidedxp
也刚接触这方面,问一个a卡要比n卡差很多吗?比如弄块rx7700 xt能和n卡啥级别的显卡相比?
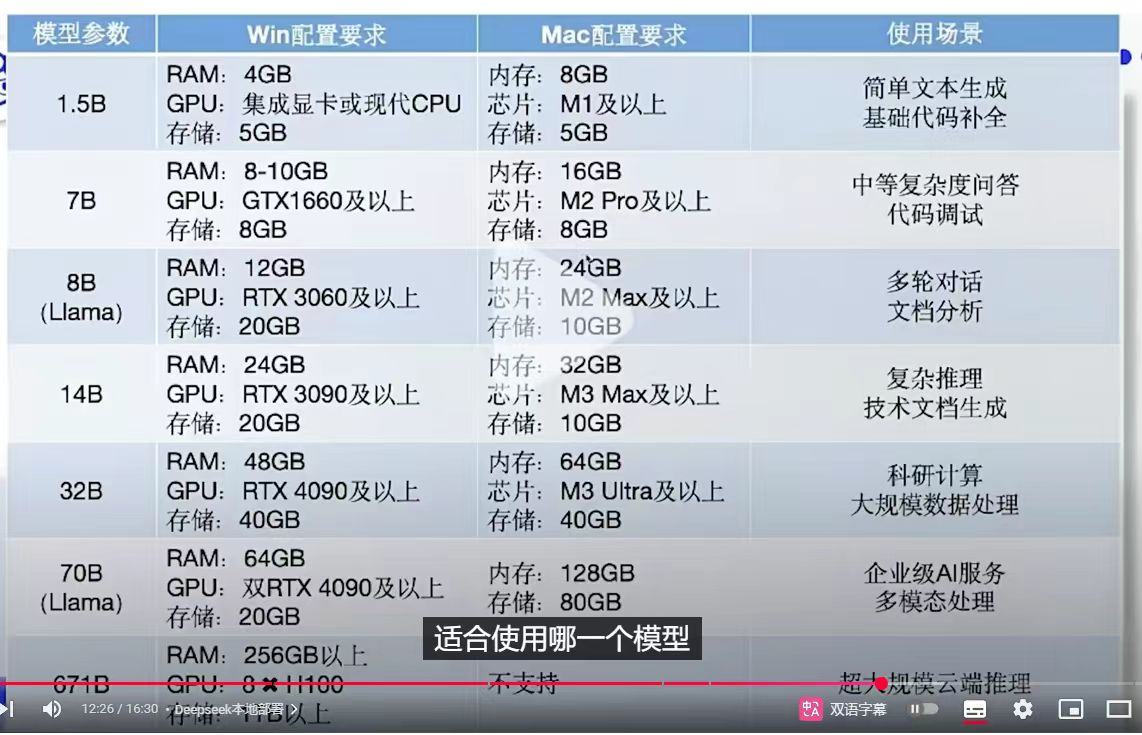
是的,AMD Radeon RX 7700 XT可以支持运行DeepSeek模型,但具体支持的模型规模和使用场景存在一定限制。以下是关键信息总结:
### 1. **支持的模型规模**
- **RX 7700 XT显存容量为12GB**,根据AMD官方说明,该显卡最多支持运行蒸馏后的**DeepSeek-R1-Distill-Qwen-14B**模型。
- 更高参数的模型(如32B、70B)需要更大的显存容量(如24GB以上)或多卡并行,因此需搭配更高端的显卡(如RX 7900 XTX或A100)。
### 2. **硬件与驱动要求**
- **驱动与软件支持**:需安装AMD Adrenalin Edition 25.1.1及以上版本的驱动,并配合LM Studio等工具进行一键式安装和优化。
- **PyTorch框架兼容性**:AMD ROCm平台已逐步支持RX 7000系列显卡的AI计算,但PyTorch对AMD显卡的支持仍处于“实验性”阶段,可能需要手动适配代码。
### 3. **性能与适用场景**
- **推理效率**:在单卡推理场景下,RX 7700 XT可满足中小型模型(如14B参数以下)的本地部署需求,适用于文本生成、代码生成等轻量级任务。
- **训练限制**:由于显存和计算单元的限制,该显卡不适合大规模模型训练,多卡互联效率也显著低于英伟达的NVLink技术。
### 4. **性价比与功耗考量**
- **价格优势**:目前RX 7700 XT海外价格已降至约353美元(约合人民2500元),显存容量和光栅性能优于同价位的RTX 4060,但功耗较高(355W vs 英伟达显卡的更低功耗设计)。
- **长期成本**:需考虑电费和多卡部署时的机架、散热成本。
### 5. **生态与开发者支持**
- **工具链成熟度**:AMD的AI生态仍落后于英伟达的CUDA,例如Hugging Face模型移植需额外适配时间,且企业级支持较弱。
- **未来潜力**:随着OpenXLA编译器的发展和PyTorch对非CUDA硬件的优化,AMD显卡的AI支持有望逐步提升。
### 总结
**适合使用RX 7700 XT运行DeepSeek的场景**:
- 个人开发者或中小型团队本地部署轻量级AI模型(如14B参数以下)。
- 预算有限且愿意投入时间进行生态适配的技术爱好者。
**不推荐场景**:
- 需要复现顶级论文或企业级大规模AI开发。
- 对即插即用和生态成熟度要求较高的用户。
若需进一步优化性能,建议结合Ryzen AI CPU(如Ryzen 8040系列)以提升端侧AI计算的效率。