自英国计算机科学家阿兰·图灵(Alan Turing)于1950年提出关于判断机器是否能够思考的著名试验“图灵测试”以来,该测试就被视为判断计算机是否具有模拟人类思维能力的关键。近期,OpenAI开发的GPT-4模型完成了这项闻名全球的测试,再度引发广泛关注。
加州大学圣地亚哥分校认知科学系博士生Cameron R. Jones和教授Benjamin K. Bergen在预印本arXiv上发表的最新论文表明,越来越多的人难以在图灵测试中区分GPT-4和人类。

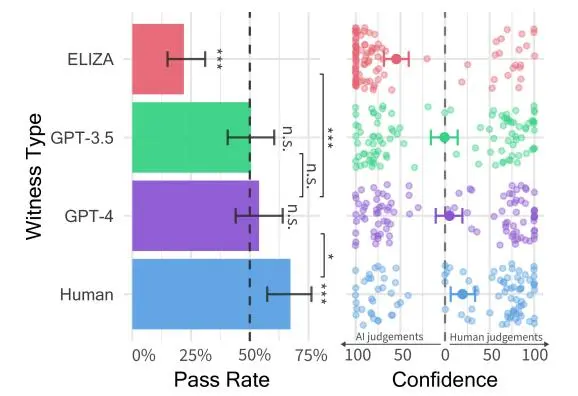
两位研究人员以真人、初代聊天机器人ELIZA、GPT-3.5和GPT-4为研究对象,试图了解谁在诱使人类参与者认为它是人类方面表现最成功。结果显示,多达54%的参与者将GPT-4误认为真人,是迄今为止首次有AI模型以如此高的结果通过图灵测试。
还需要指出的是,上述研究开展之时,OpenAI尚未宣布新一代的旗舰模型GPT-4o,如果参与测试的是GPT-4o,这一比例可能还会更高。
GPT-4通过图灵测试,54%的人将其误认为真人
上述研究人员招募了500名参与者,让他们与四位“对话者”进行五分钟的交流,这四位“对话者”分别是真人、初代聊天机器人ELIZA、GPT-3.5和GPT-4。参与者在对话结束后需判断对方是人还是机器。(注:ELIZA是由麻省理工团队在1964年至1966年期间开发的史上第一个聊天机器人,上世纪60年代曾参与图灵测试,但宣告失败。该机器人没有大语言模型或神经网络支持。)
双方将通过一个类似即时通讯应用的界面进行交流。界面底部有一个聊天输入框,屏幕中央为对话记录,顶部有一个计时器和触发帮助和报告的按钮。招募到的参与者首先发送消息,双方交替发送,每条消息限制在一定的字符数内。
针对AI语言模型,研究人员基于表现最好的GPT-4命令集(提示词)进行了修改,指示其表现得像一个年轻人,不要太认真对待游戏,使用口语化表述,且不要出现拼写和语法错误。此外,AI模型也不能提供太多的知识,尤其是语文和数学方面的知识。每轮测试开始时,还会添加一些额外的信息,如姓名、地点和时间戳。
而且,为了模拟真实的交流延迟,AI的回复会根据消息的长度人为地延迟发送。这种设置旨在模拟正常的人际交流节奏,增加实验的现实感。研究小组解释称,人类之所以不能百分之百地识别同类,是因为提问者认为AI的效率越来越高。这增加了他们将人类错误地识别为机器的可能性。
为了深入了解影响参与者最后作出决定的定性因素,研究小组对其使用的策略和判断的理由进行了分类。36%的参与者与“对话者”进行闲聊,询问个人细节或他们的日常活动;第二类策略是社交和情感(25%),例如询问“对话者”的意见、经历并分析判断它们的幽默感;第三类是知识和推理(13%),包括数学、逻辑和常识问题。
结果显示,有54%的参与者将GPT-4误认为是真人。相比之下,预先设定好回复的ELIZA只有22%的人将其认作真人,GPT-3.5则为50%,而“真人对话者”被正确辨认的比例则为67%。
决策依据表明,社交情感能力是关键
研究人员在论文中对“真人对话者”被正确辨认的比例只有67%感到震惊。
他们指出,这可能反映出参与者认为AI系统质量在不断进化,这一结果也与近年来其他类似的图灵测试呈现的情况类似。当AI系统能力很差时,真人是很容易被辨别出来的,而随着参与者对AI系统能力的信心增强,他们便更有可能将真人误认为AI。
作者在论文中指出,他们的结果为图灵测试提供了一些经验性证据。就他们使用的策略和给出的决策理由而言,被招募的参与者在测试中更关注的是研究对象在对话中的风格和社交情感因素,而不是更传统的智力类回答,例如知识和推理能力。他们认为,这可能是因为参与者认为,社交能力是成为机器最无法模仿的人类特征。
GPT-4和GPT-3.5在测试中的表现虽然未达到“真人对话者”的水平,但目前AI研究者普遍认为,只要有30%的回答被误认为是人类,那就算通过测试。不过也有观点认为,50%的基线更加合理,因为它更能证明人类在识别AI方面并不具有偶然性。
在上述研究中,参与者的置信度得分和决策依据都表明他们并非随意猜测:GPT-4是人类的平均置信度为73%。
还需要指出的是,由于研究人员在进行上述实验时,OpenAI尚未宣布新一代的旗舰模型GPT-4o。这一全新模型可以利用语音、视频和文本信息进行实时推理,如果参与测试,被参与者误认为人类的结果可能就会更高。
图灵测试是由英国计算机科学家阿兰·图灵(Alan Turing)于1950年在其论文《计算机器与智能》中提出的一个关于判断机器是否能够思考的著名试验,测试某机器是否能表现出与人等同或无法区分的智能水平。1966年,美国计算机协会(ACM)还以图灵的名字设立了图灵奖,被誉为“计算机界的诺贝尔奖”,旨在奖励对计算机事业作出重要贡献的个人,每年颁发一次。