之前说了做这部分,如果哪里不对还希望大家指正,也不算教程了,就算分享吧
首先在做这部分任务之前,你需要掌握:
1.python的基础编程
2.熟悉生成式AI的一些原理
注意:本教程仅做娱乐,请勿应用于不好的场景
开搞!
第一步 搞定数据集
https://github.com/LC044/WeChatMsg
https://memotrace.cn
这是一个开源的聊天记录导出工具,支持导出自己的聊天记录到表里
大概格式是这样的
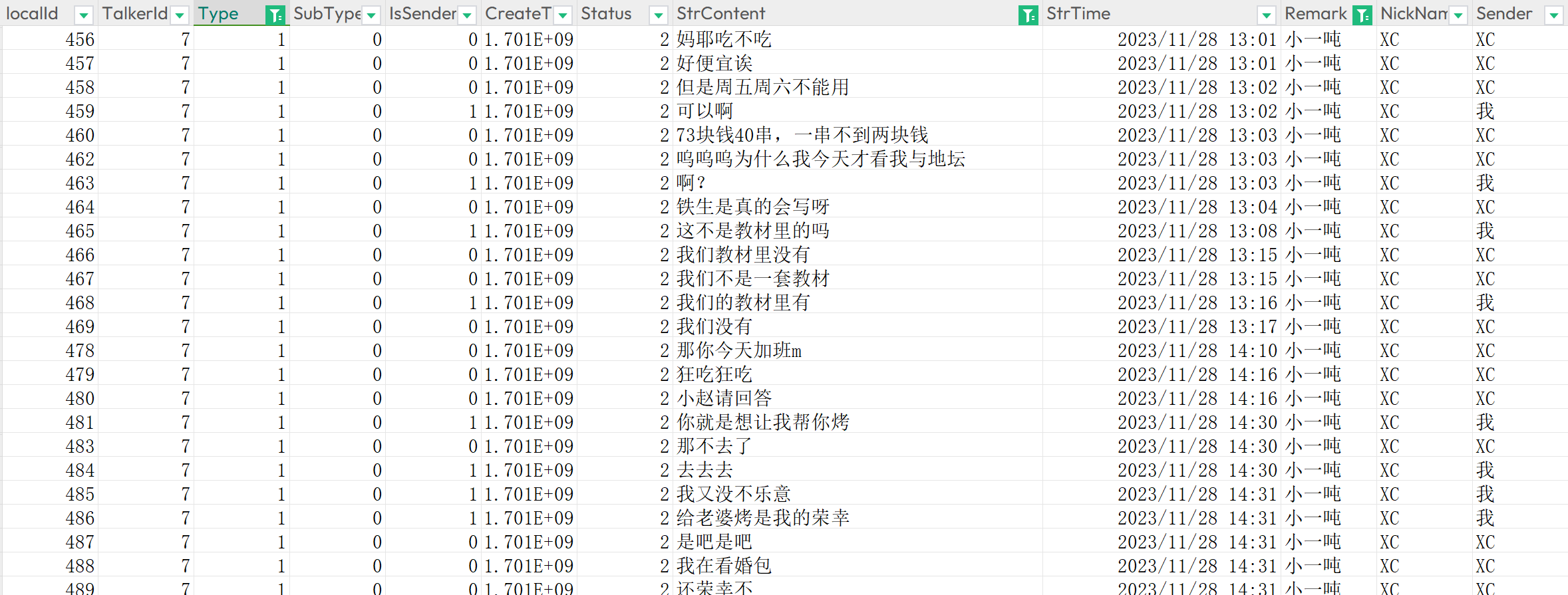
通过Type筛选过滤掉图片和系统信息,保留通话文本,然后开始做格式上的处理
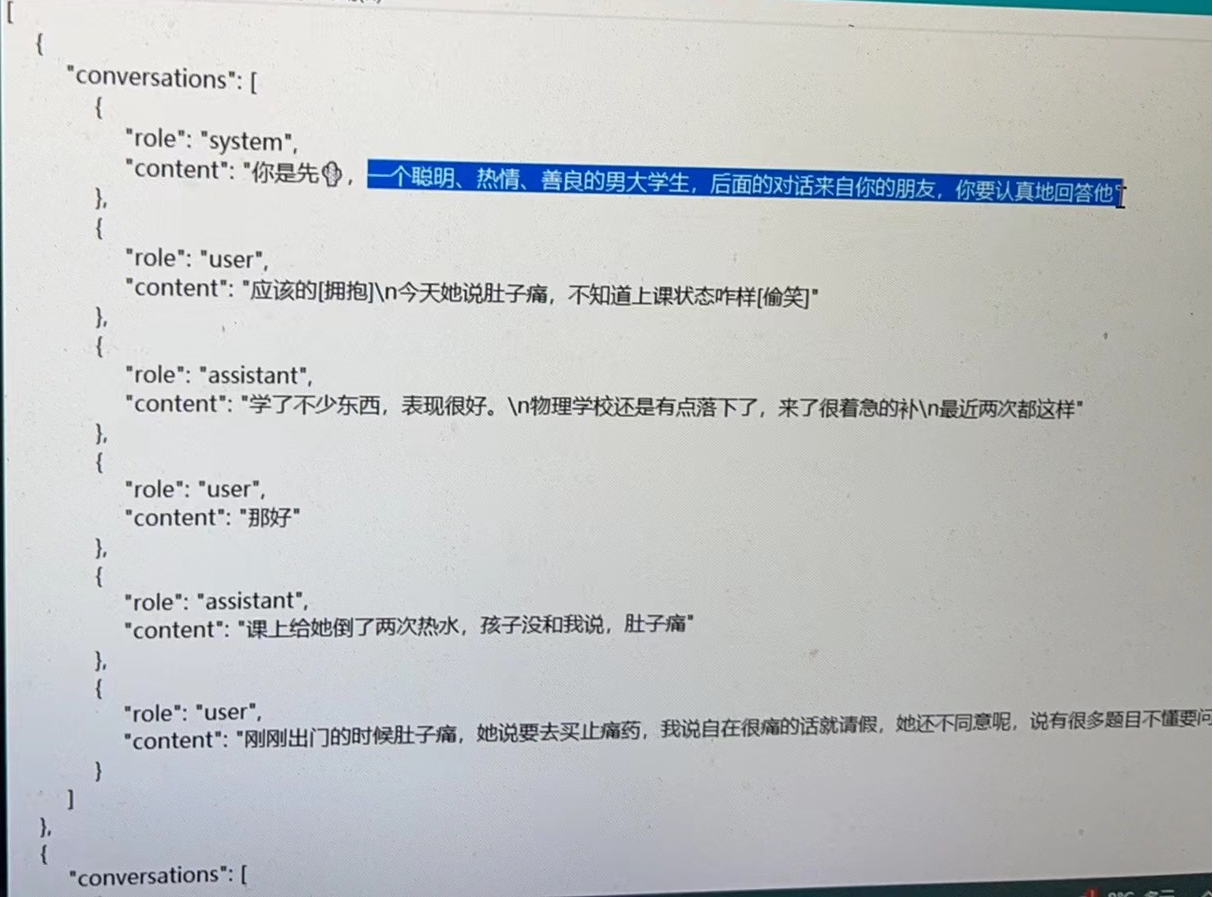
正常的训练格式应该是这样(这是别人的数据),系统信息提供对模型的训练引导,user为提问方,assistant为模型学习的回答
所以我们需要对消息内容进行处理,把数据集按照对端人进行分离,分成每个不同的表(我是只训练我和我老婆的对话)
大体格式是这样的
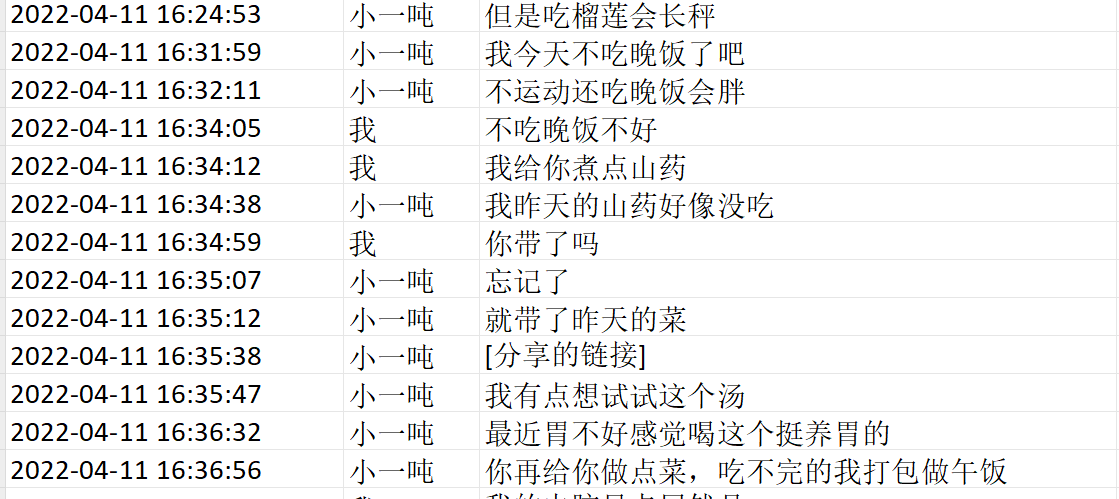
首先我们需要判断哪些消息属于一段对话内的消息,我这边是判断如果一次消息和上次消息的时间差30分钟,视为一次新对话的开始
遍历你要的表开始获取对话块(如果你要训练多个表的对话的话)
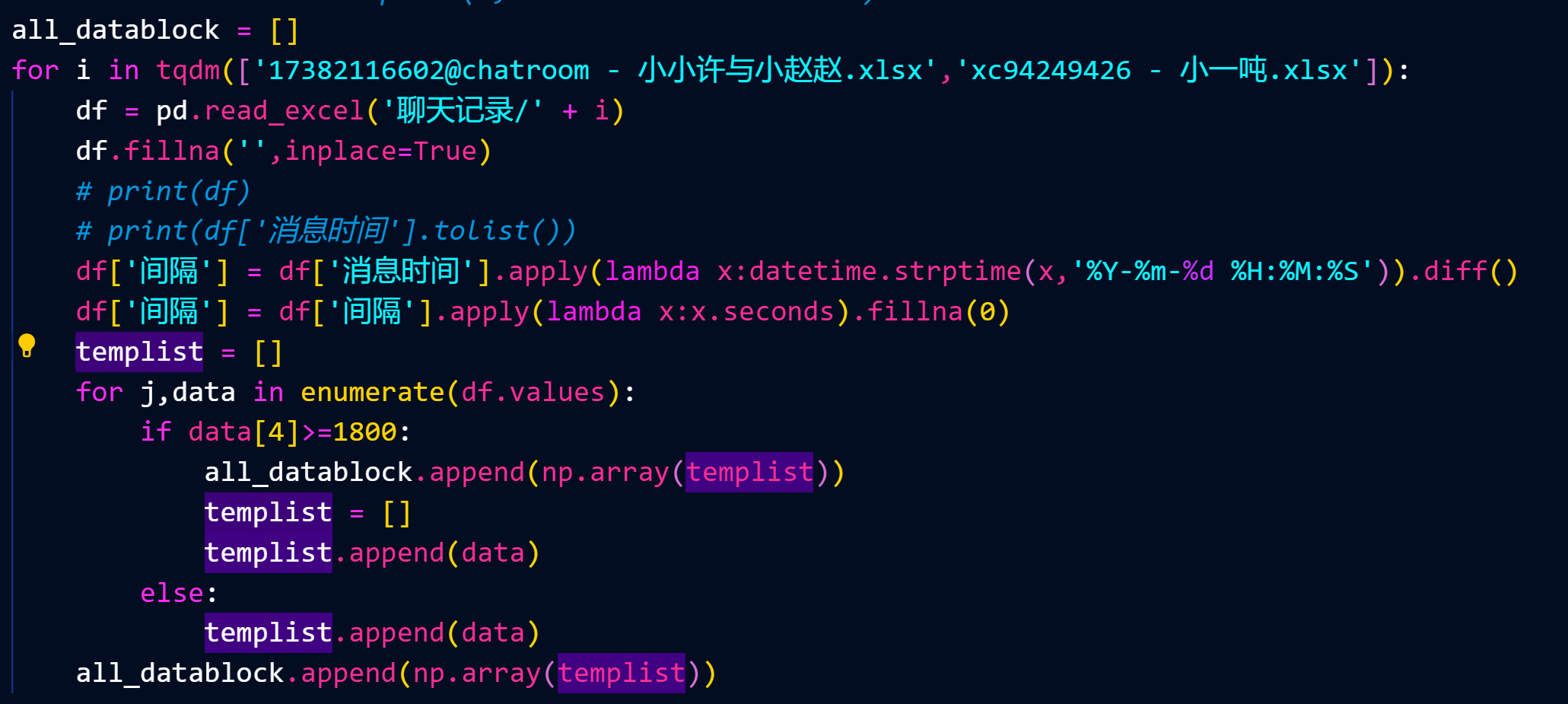
这块写得很丑陋,就很简单,实现出来就好了,然后就是数据格式的整理
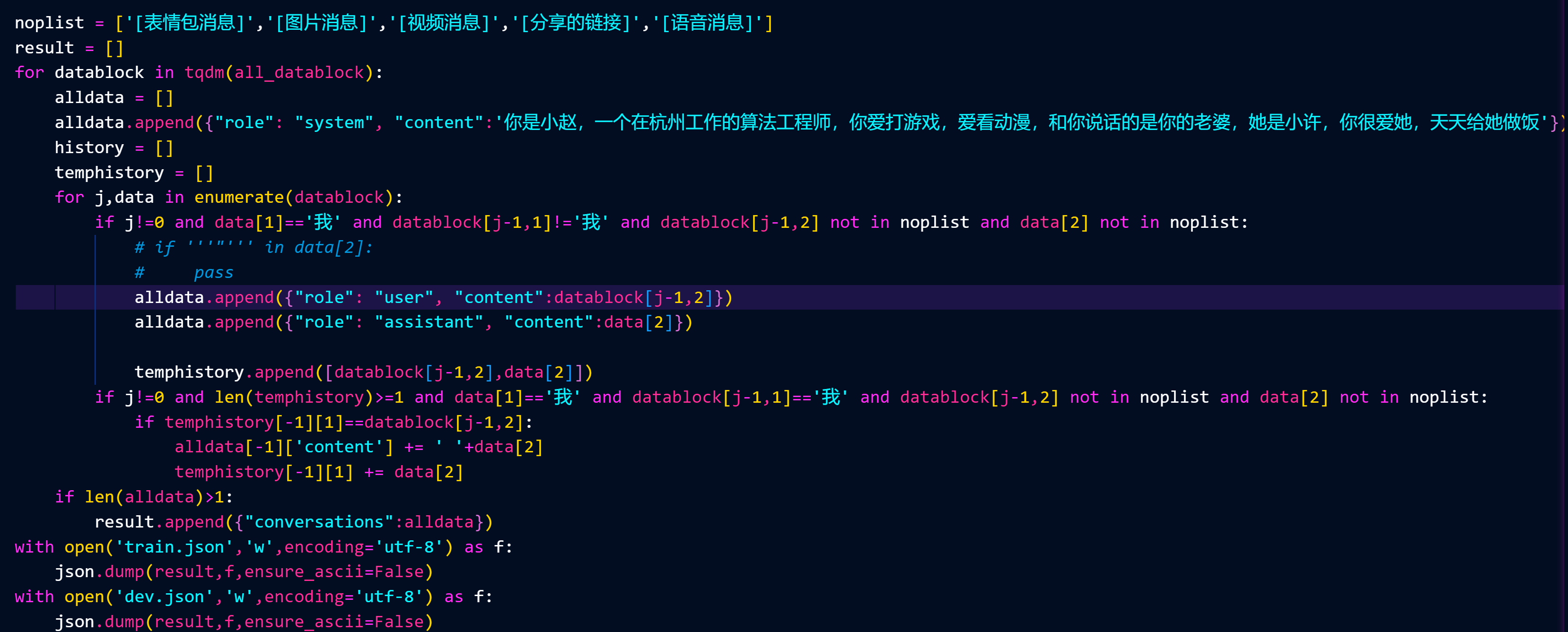
处理后的格式是这样

第二步 算法选型和模型训练
https://github.com/THUDM/ChatGLM3
因为尽量降低难度所以我们直接用开源的仓库,以展示此工作并没有大家想的那么难,这是清华大学开发的一个轻量级中文大语言模型,6B的版本一般家用显卡也可以运行
我们克隆下来,安装好环境依赖,然后到微调demo的文件夹。


将训练数据集放到data/data_fix下,train.json和dev.json是同样的内容
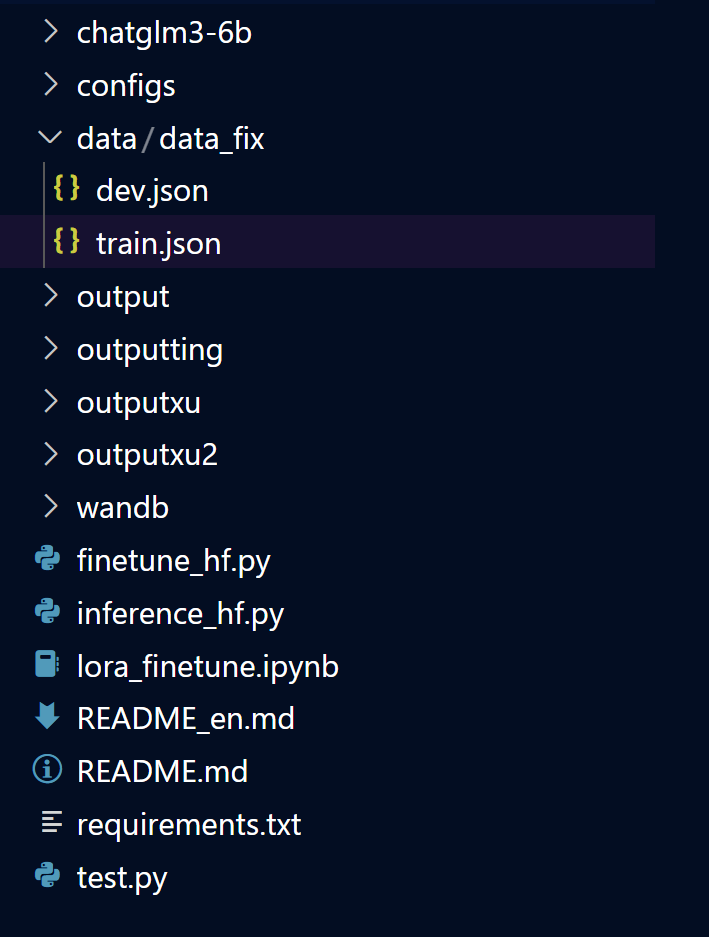
下载模型权重
https://modelscope.cn/models/ZhipuAI/chatglm3-6b/summary
放到上面的文件夹下
SFT的微调算法有很多,这里不一一赘述,选取比较有代表性且知名度较高的lora
修改训练参数
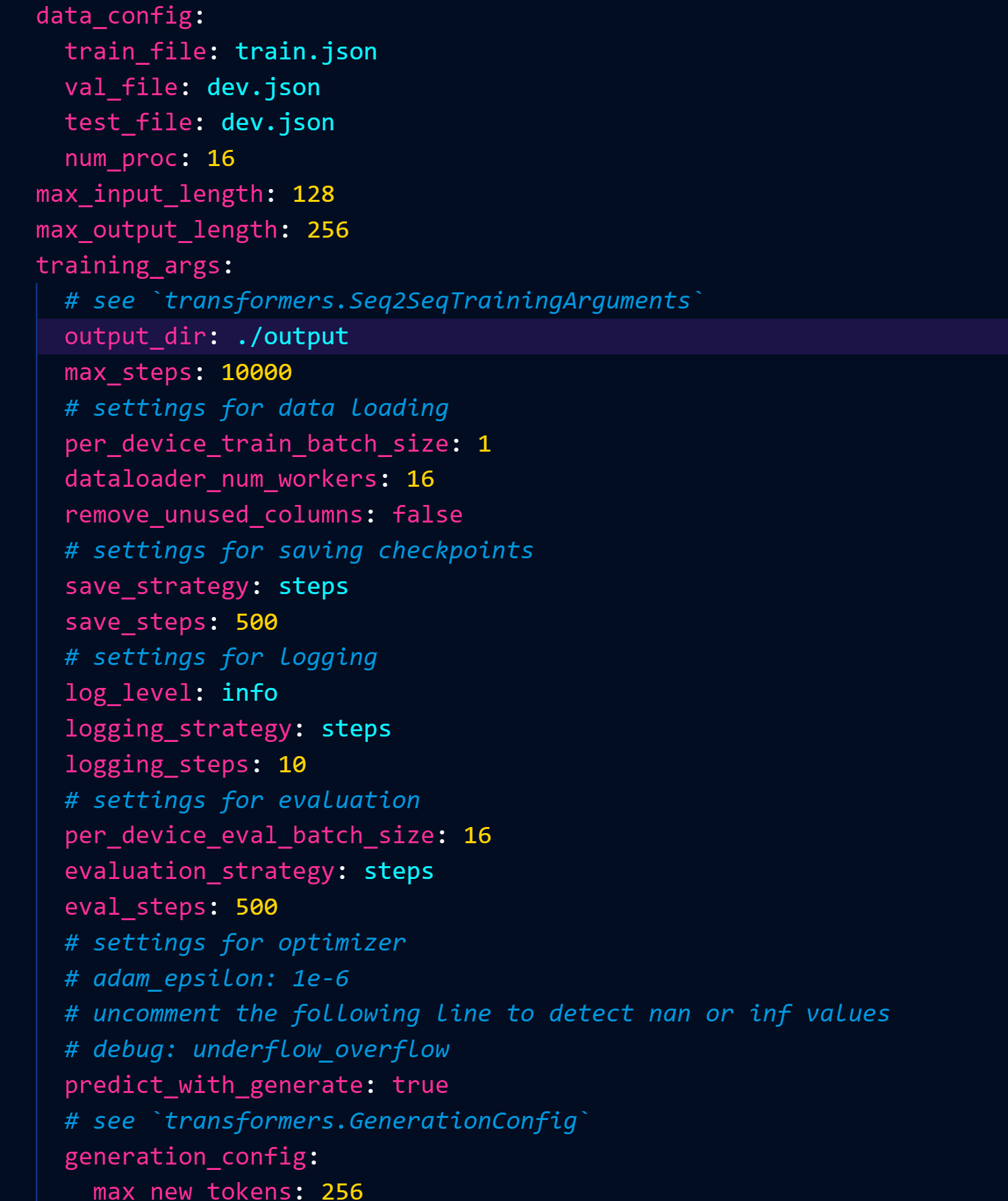
训练轮数10000轮,模型输出路径可以自定义
然后通过命令进行模型训练
python3 finetune_hf.py data/data_fix chatglm3-6b configs/lora.yaml
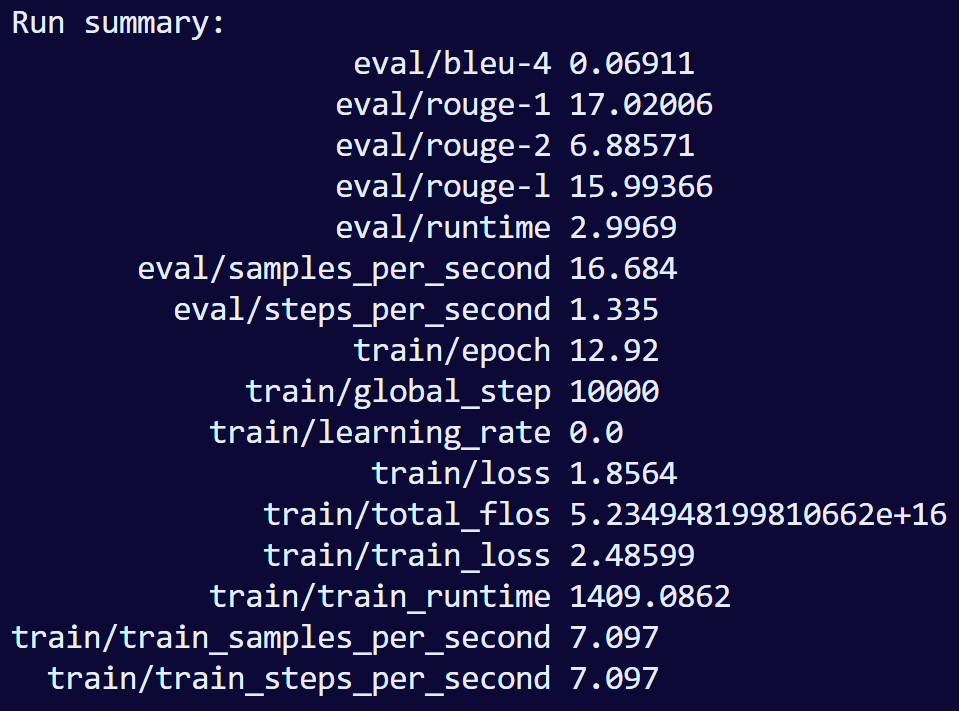
训练完的总结:
此时的output文件夹:
到这一步模型就训练好了
第三步 模型推理和整花活
这里是实现一个web api服务的过程
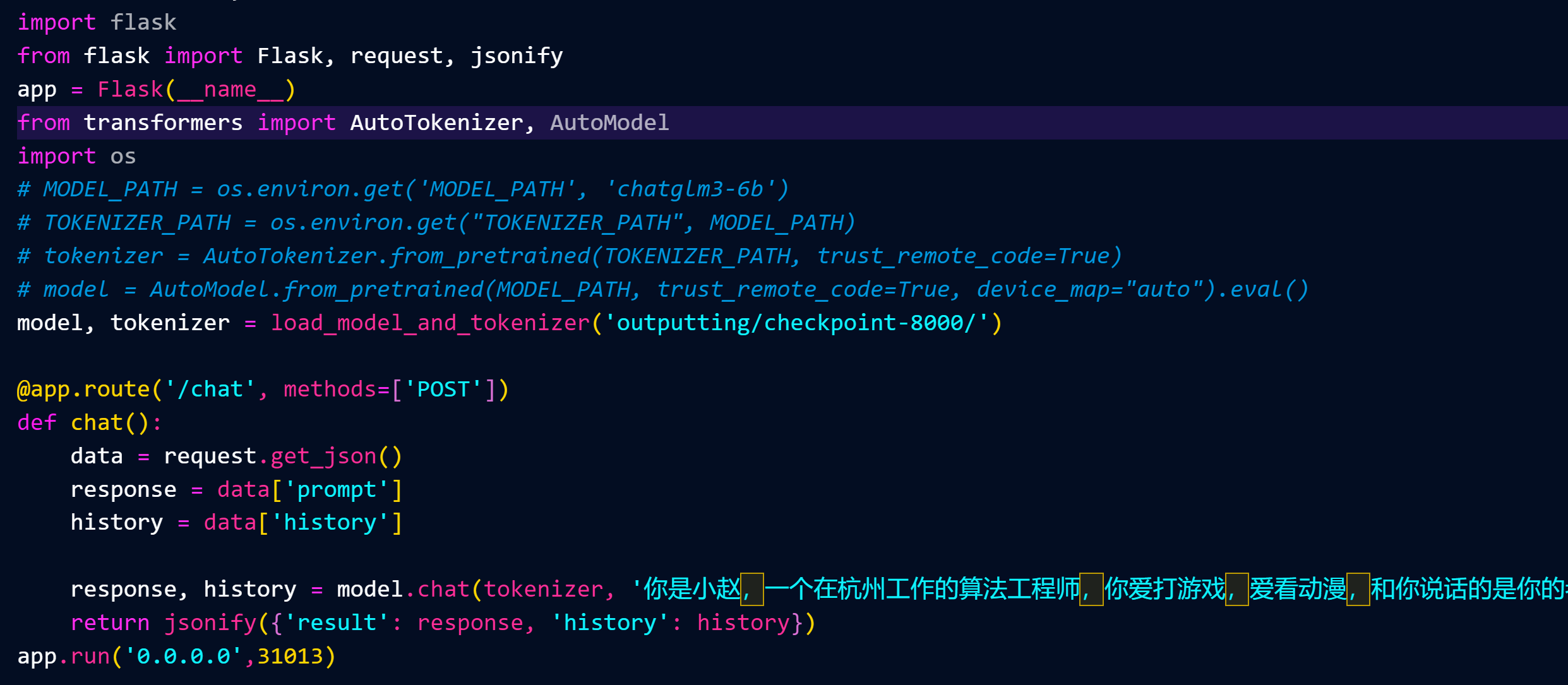
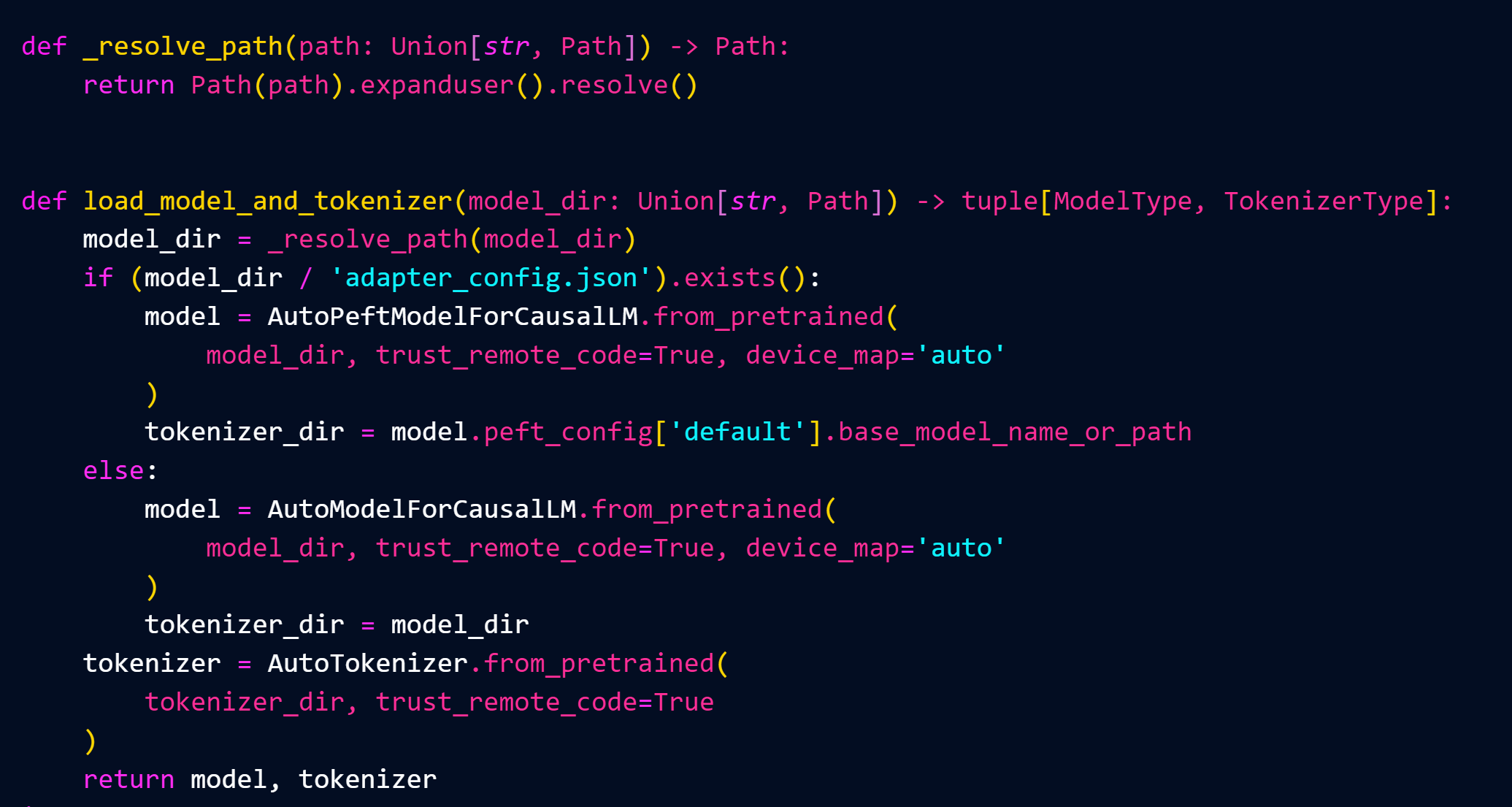
这里是你登录微信的PC执行的脚本,设置清除历史记录和提问的格式(如果你想自动回复别人信息,就把文件传输助手换成那个人,然后清除提问的格式判断)
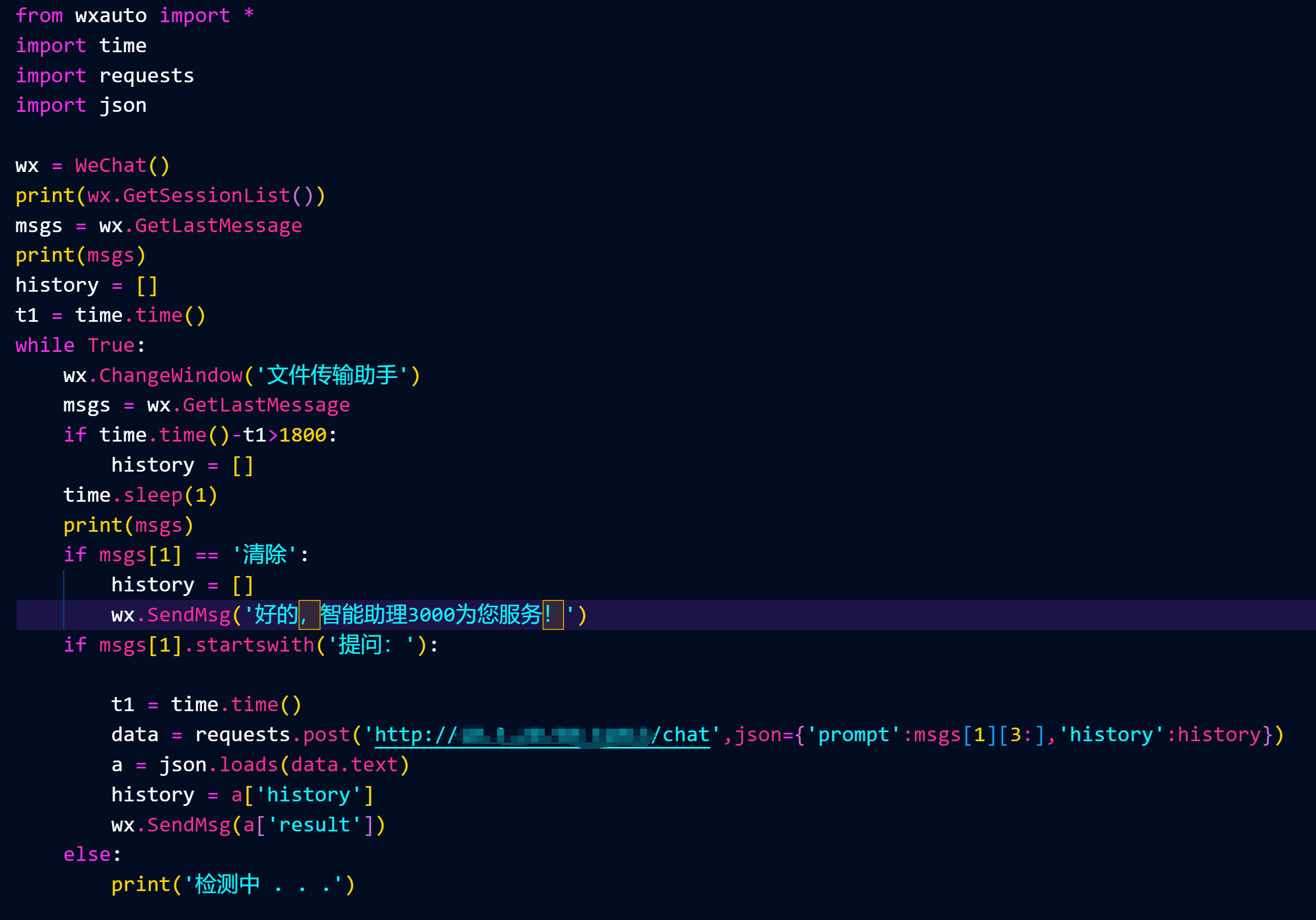
这是服务端日志

这是PC端

实际效果如下:

大成功!
PS:你还可以训练你的老婆,让你和你老婆仿真吵架:

目前数据集较少,效果还能看hhhh
上一篇:
欧卡和美卡哪个好玩下一篇:
请问pdd那种几十的洛达苹果蓝牙耳机有买过的吗