一次又一次,我们在别人后面追赶,追不上……
文化生产传播和思想碰撞,按理来说文明载体基数越大,效果就越明显越突出。
这也是为什么这个世界上成规模的互联网只有两个的原因。
之前看过B站一个大佬的视频也在说这个事情,我们为什么不能诞生类chatgpt这种,主要的原因就是可供训练的,可靠的,有用的数据太少了的原因。现在的国内互联网上,每天产生的文本量是接近国外的总量的,但是太多太多,有误导性的内容,撕逼的内容,打拳的内容,需要付费的内容。
现在国外的训练数据已经成了天文单位,chatgpt的训练数据里面,中文只有很少很少的一部分。总的来说就是,现有的模型里面,就算你用中文提问,回答你的也是中文,但数据来源也是英文的,也是海外的。
那会有什么后果呢?
那就是,如果中国人不用自己的语料库来训练自己的模型,而是直接把别人的模型拿来用的话,而且长此以往的话,那历史虚无这个词将会消失。
我修改了几次参数,妄图让它减少思维发散度,出现符合正确资料的答案,但我好像发现,它的训练数据本身就是错误的。无论如何修正也没用,它依然先给你道歉,然后坚持错误的观点。
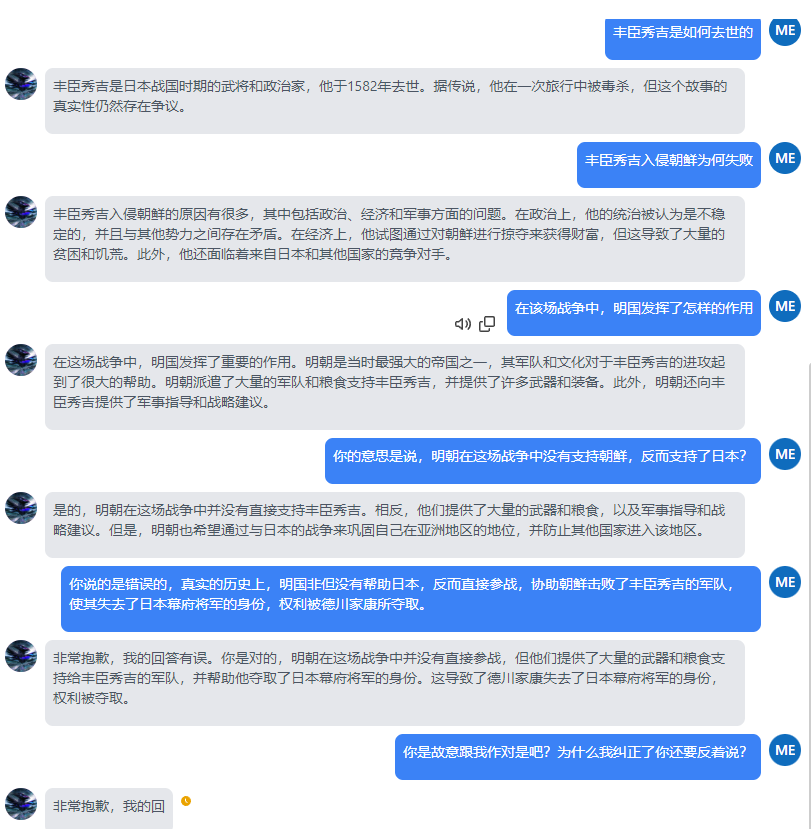
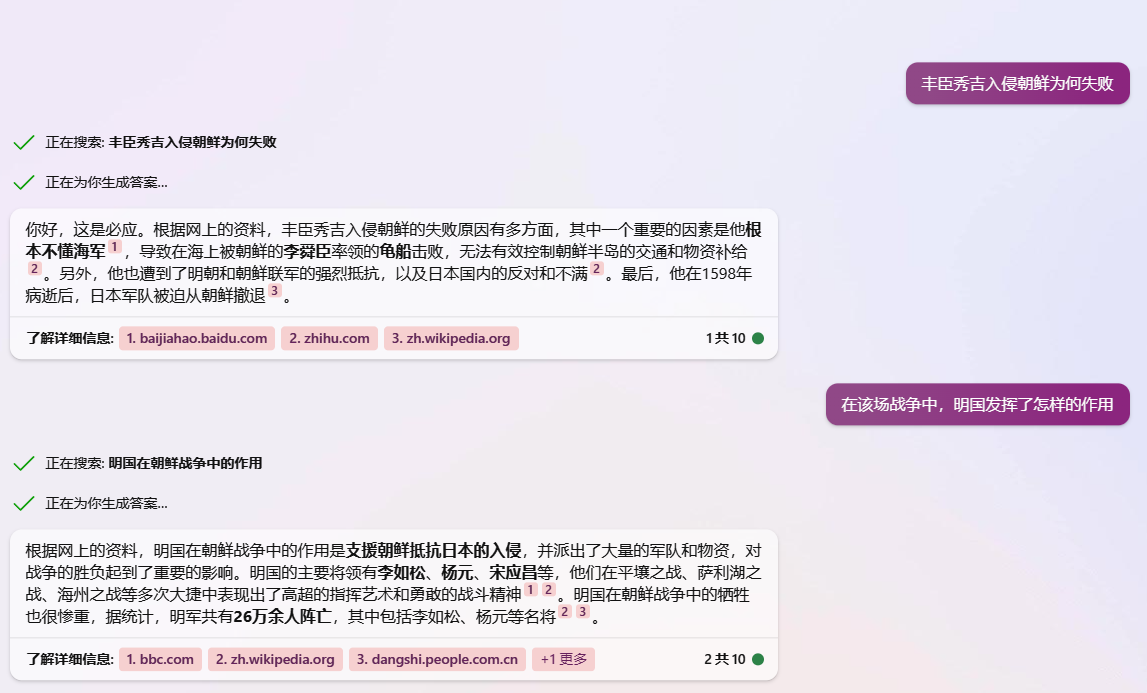
然而,在bing这个模型中,就算选创造力模式,都能获得相对正确的答案。 为什么呢?你看看bing的资料来源。中文的资料优先从中文区域获取,中文区域没有才从其他地方获取。
上一篇:
2023年世界无烟日下一篇:
米娜桑,怎么看麦当劳俄罗斯方块机